

1. JPA简介
1.1 概念
JPA顾名思义就是Java Persistence API的意思,是JDK 5.0注解或XML描述对象-关系表的映射关系,并将运行期的实体对象持久化到数据库中。
1.2 优势
1.2.1 标准化
JPA 是 JCP 组织发布的 Java EE 标准之一,因此任何声称符合 JPA 标准的框架都遵循同样的架构,提供相同的访问API,这保证了基于JPA开发的企业应用能够经过少量的修改就能够在不同的JPA框架下运行。
1.2.2 容器级特性的支持
JPA框架中支持大数据集、事务、并发等容器级事务,这使得 JPA 超越了简单持久化框架的局限,在企业应用发挥更大的作用。
1.2.3 简单方便
JPA的主要目标之一就是提供更加简单的编程模型:在JPA框架下创建实体和创建Java 类一样简单,没有任何的约束和限制,只需要使用 javax.persistence.Entity进行注释,JPA的框架和接口也都非常简单,没有太多特别的规则和设计模式的要求,开发者可以很容易的掌握。JPA基于非侵入式原则设计,因此可以很容易的和其它框架或者容器集成。
1.2.4 查询能力
JPA的查询语言是面向对象而非面向数据库的,它以面向对象的自然语法构造查询语句,可以看成是Hibernate HQL的等价物。JPA定义了独特的JPQL(Java Persistence Query Language),JPQL是EJB QL的一种扩展,它是针对实体的一种查询语言,操作对象是实体,而不是关系数据库的表,而且能够支持批量更新和修改、JOIN、GROUP BY、HAVING 等通常只有 SQL 才能够提供的高级查询特性,甚至还能够支持子查询。
2. JPA、hibernate、SpringDataJpa关系
JPA仅仅是一种规范,也就是说它仅仅定义了一些接口,而接口是需要实现才能工作的。所以底层需要某种实现,而Hibernate就是实现了JPA接口的ORM框架。
SpringDataJpa是Spring提供的一套简化JPA开发的框架,按照约定好的方法命名规则来创建DAO层接口,就可以在不写接口实现的情况下,实现对数据库的访问和操作。并且提供了一些常用的增删改查等方法的直接操作。 SpringDataJpa可以理解为JPA规范的再次封装抽象,底层还是使用了Hibernate的Jpa技术实现。
3. 集成步骤
3.1 引入SpringDataJpa所需依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<!-- MySQL连接 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
通过观察依赖包,我们也能够发现其实他还是使用了hibernate:
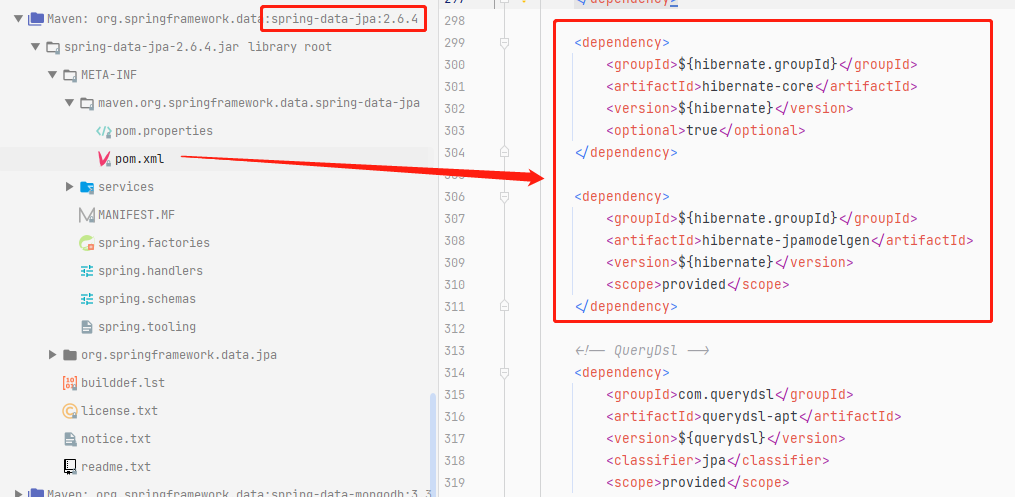
3.2 配置数据库连接
新建application.properties配置文件
server.port=8081
#mysql
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
spring.datasource.url=jdbc:mysql://localhost:3306/learn-springboot?serverTimezone=Asia/Shanghai&characterEncoding=utf-8&useSSL=false
spring.datasource.username=root
spring.datasource.password=123456
#jpa
# 是否在日志里显示sql
spring.jpa.show-sql=true
# 数据库类型
spring.jpa.database=mysql
spring.jpa.database-platform=org.hibernate.dialect.MySQL5Dialect
#指定为update,每次启动项目检测表结构有变化的时候会新增字段,表不存在时会 新建,如果指定create,则每次启动项目都会清空数据并删除表,再新建
spring.jpa.hibernate.ddl-auto=update
#指定jpa的自动表生成策略,驼峰自动映射为下划线格式
spring.jpa.hibernate.naming.implicit-strategy=org.hibernate.boot.model.naming.ImplicitNamingStrategyLegacyJpaImpl
3.3 实体类
package com.world.lzh.entity;
import lombok.Data;
import javax.persistence.*;
import java.util.Date;
/**
* @Author lzh
* @Date 2022/5/12 - 9:13
* @Description
* @Version 1.0.0
**/
@Data
@Entity
@Table(name = "t_user")
public class User {
/**
* 主键生成策略: 自增
*/
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer id;
private String name;
private Integer age;
private String address;
private Date createTime;
private Date updateTime;
}
这里有几个特殊的注解
@Entity: 标识这是一个实体类
@Table: 标识与之映射的表名
@Id: 标识数据库主键
@GeneratedValue: 标识主键生成策略,这里是自增。
3.4 Dao层
Dao层主要处理和数据库的交互,这里我们可以使用JPA为我们提供的基类:JpaRepository,里面包含了大部分常用操作。只需集成即可。
package com.world.lzh.dao;
import com.world.lzh.entity.User;
import org.springframework.data.jpa.repository.JpaRepository;
import java.io.Serializable;
/**
* @Author lzh
* @Date 2022/5/12 - 9:14
* @Description
* @Version 1.0.0
**/
public interface UserDao extends JpaRepository<User, Integer>, Serializable {
}
3.5 Service层
package com.world.lzh.service.impl;
import com.world.lzh.dao.UserDao;
import com.world.lzh.entity.User;
import com.world.lzh.service.UserService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
/**
* @Author lzh
* @Date 2022/5/12 - 9:17
* @Description
* @Version 1.0.0
**/
@Service
public class UserServiceImpl implements UserService {
@Autowired
private UserDao userDao;
@Override
public String save(User user) {
userDao.save(user);
return "新增成功";
}
@Override
public Object select(User user) {
return userDao.findById(user.getId());
}
}
4. 测试
我们使用apipost进行测试
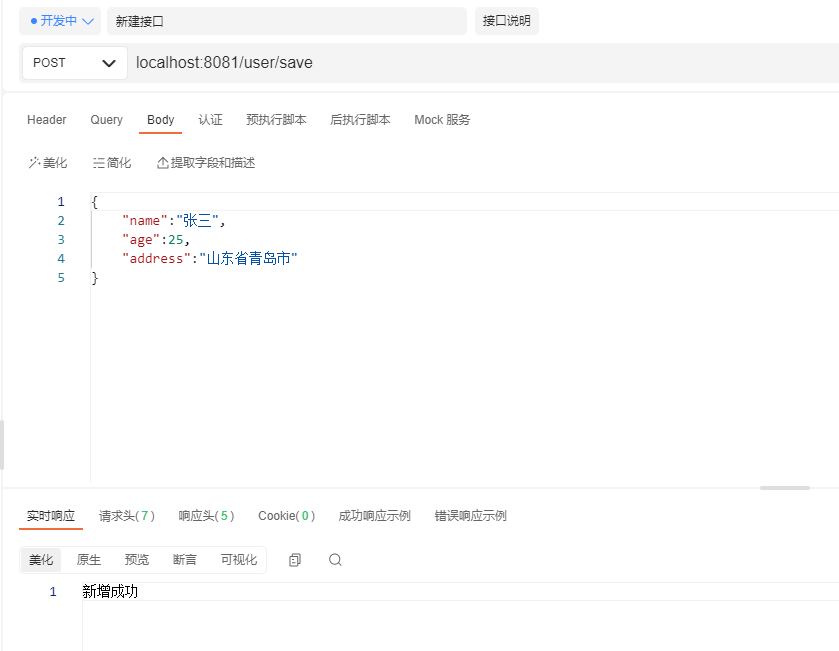
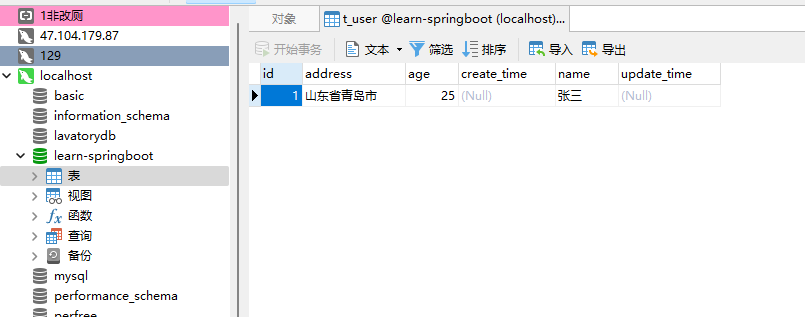
查看数据库
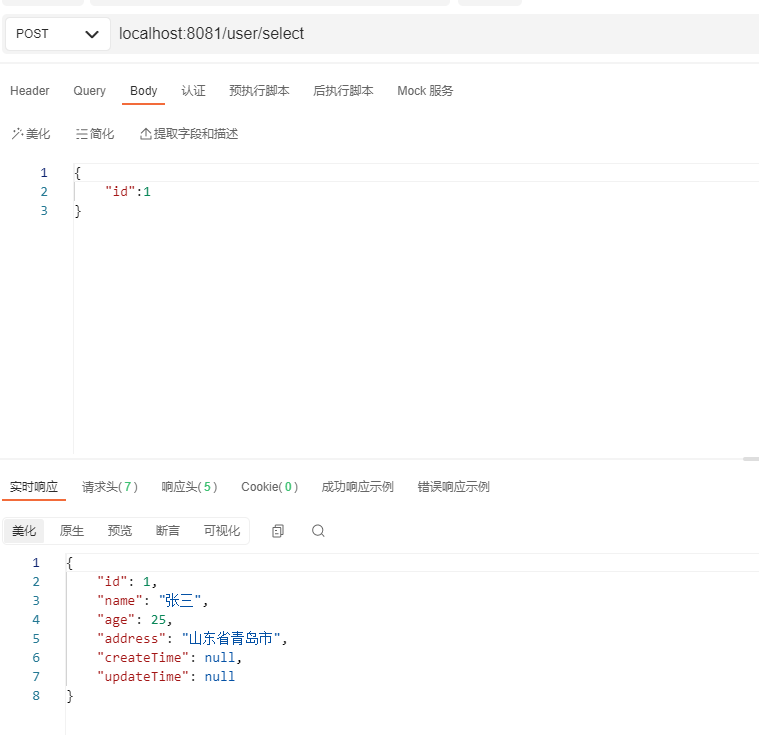
接下来我们访问查询接口
5. 总结
关于JPA的简单集成大概就介绍这么多,JPA的思想主要是通过对象操作数据库,相比于mybatis更加ORM, 所以相比之下,也有人把mybatis比作是一个半ORM的框架,主要原因就是sql和HQL的区别,这个如果使用的hibernate的同学应该更有感触。
关于JPA和Mybatis的选择问题,这个之一在网络上争论不断,这个其实也没有什么好坏之分,是要能实现我们的目的,选择那种框架只不过是其中的一种手段罢了。而像我确实还是用mybatis-Plus比较多。可能用的多了,也就感觉它更方便一些
源码地址:点击访问欢迎评论star⭐